핵심 요약
Zhipu AI·Tsinghua University가 발표한 GLM-5는 에이전트형 코딩과 추론 성능을 동시에 겨냥한 차세대 기초모델입니다. 공개 논문 기준으로 GLM-5는 744B(활성 40B) 규모와 28.5T 토큰 학습, 비동기 강화학습 파이프라인을 결합해 이전 버전 대비 성능과 효율을 함께 개선했다고 보고했습니다.
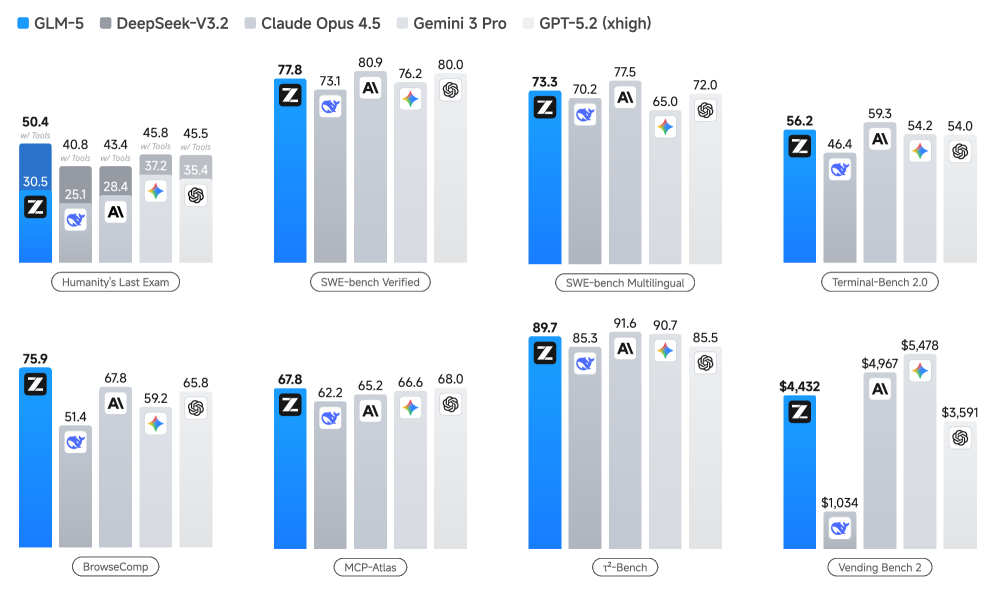
이미지 출처: arXiv 논문 본문 Figure 1
무엇이 달라졌나
- 아키텍처: DSA(DeepSeek Sparse Attention)를 채택해 장문맥 처리 성능을 유지하면서 학습·추론 비용을 낮추는 방향을 제시했습니다.
- 학습 인프라: 생성과 학습을 분리한 비동기 강화학습 인프라를 도입해 후학습 효율을 높였다고 설명했습니다.
- 에이전트 강화학습: 장기 과제 상호작용에서 계획·자기수정 능력 향상을 목표로 비동기 에이전트 강화학습 알고리즘을 추가했습니다.
- 오픈 배포: 코드·모델 정보를 공식 저장소로 공개해 재현성과 확산 가능성을 높였습니다.
수치/스펙/벤치마크
- 총 파라미터: 744B (활성 파라미터 40B)
- 총 학습 토큰: 28.5T
- 문맥 확장: 4K → 200K (중간 학습 단계)
- 벤치마크 성과(논문 주장): GLM-4.7 대비 평균 약 20% 개선
- 지표: Intelligence Index v4.0에서 50점 (오픈 웨이트 리더)
- 장기 과제: Vending-Bench 2 최종 잔고 $4,432 보고
산업/비즈니스 맥락(해석)
이번 공개는 “오픈 웨이트도 에이전트형 실무 코딩에 본격 진입”이라는 신호로 읽힙니다. 특히 정적 벤치마크보다 장기 과제(코드 작성·수정·반복 검증) 성능을 전면에 내세운 점은, 기업 도입 평가 기준이 단일 점수에서 실제 워크플로우 완주율로 이동하고 있음을 보여줍니다.
동시에 논문 수치와 실제 운영 성과 사이에는 환경 편차가 존재할 수 있으므로, 도입 기업은 내부 코드베이스 기반 사전검증(샌드박스 PoC, 보안 정책 적합성, 총소유비용)을 병행할 필요가 있습니다.
체크포인트
- 공개 저장소 기준으로 재현 실험 결과가 얼마나 빠르게 축적되는지
- 장기 코딩 과제에서 실패 유형(오작동, 무한 루프, 안전 이슈)이 어떻게 보고되는지
- 폐쇄형 상위 모델 대비 비용-성능 곡선이 실제 운영에서 유지되는지
영상 자료
영상 자료: 공식 소스에서 확인되지 않음
참조
AI 생성 고지: 본 글은 공개된 1차 소스(논문/공식 저장소)를 기반으로 AI가 초안을 작성하고 사실관계 중심으로 구조화했습니다. 해석 문단은 원문 사실과 구분해 표기했습니다.