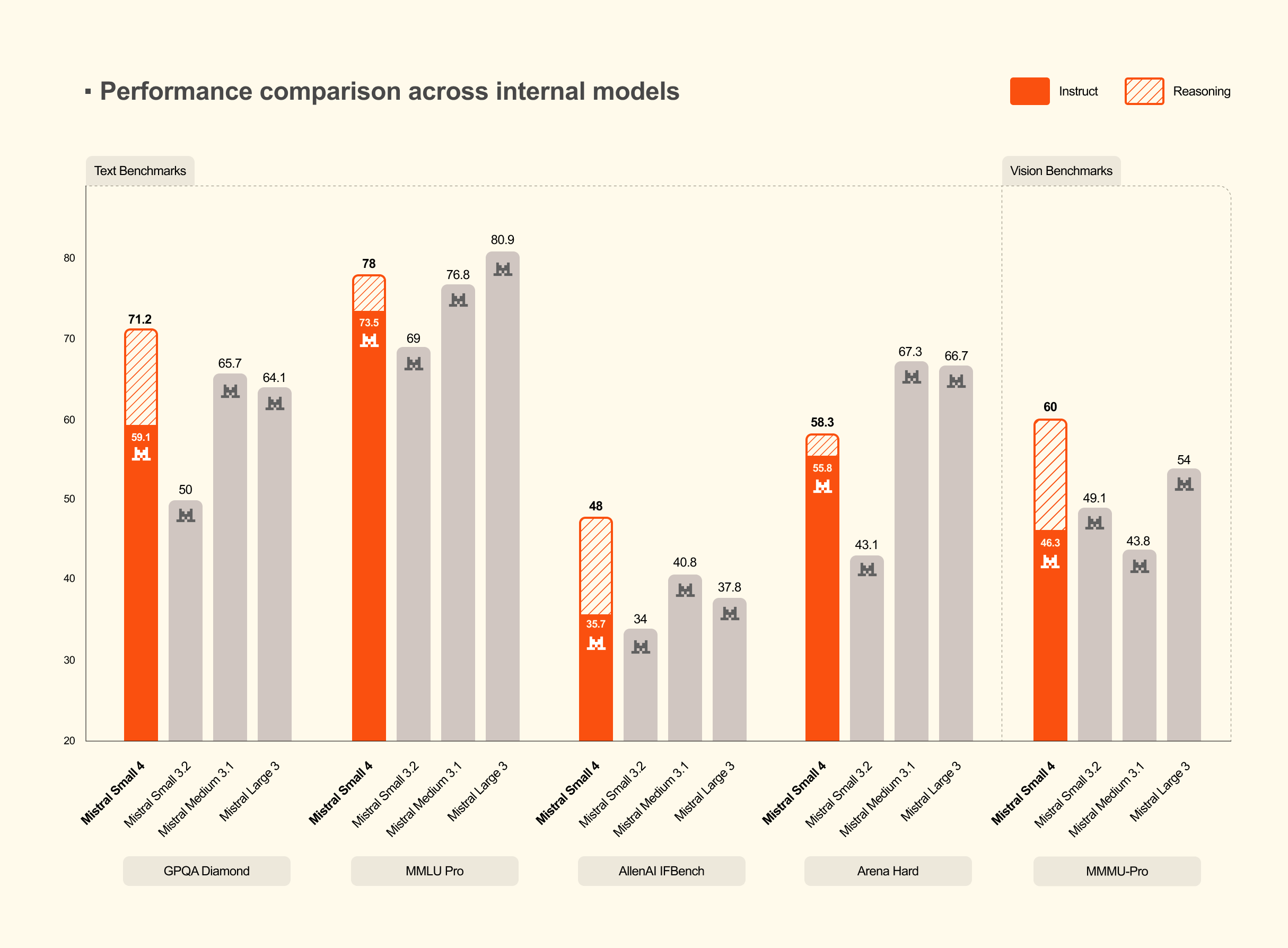
핵심 개요: Small 4의 기술 혁신
Mistral AI는 3월 17일 새로운 Small 4 모델을 공개했습니다. 혼합 전문가(Mixture of Experts, MoE) 아키텍처에 128개의 전문가 모듈을 탑재해 소형 모델의 성능 천장을 깨뜨렸습니다. 이는 오픈소스 AI 커뮤니티에서 경량 모델의 새로운 기준점을 제시합니다.
Mixture of Experts (MoE) 기술 심화 이해
기본 개념
전통적인 신경망 모델은 모든 데이터를 처리할 때 전체 파라미터를 사용합니다. 예를 들어, 1000억 파라미터를 가진 GPT-4는 모든 쿼리에 대해 1000억 개의 계산을 실행해야 합니다. 이는 매우 비효율적입니다.
MoE 기술은 128개의 “전문가” 신경망 분할 구성으로 각 입력에 대해 필요한 전문가만 활성화(희소성)하여 매개변수는 동일하지만 추론 효율이 2-3배 향상됩니다.
Small 4의 MoE 구조
- 128개 Expert 모듈: 각각 독립적인 신경망 계층 (약 10억 파라미터/각 전문가)
- Gating Network: 입력을 분석하여 최적의 2-4개 전문가만 선택하는 라우팅 메커니즘
- 활성화율: 전체 128개 중 약 3% (3-4개 전문가)만 활성화 → 계산량 97% 감소
- 총 파라미터: 1,600억 개 (이론적 용량) → 실제 활성화: 약 50억 개 (효과적 크기)
왜 더 효율적인가?
기존 모델: 모든 입력에 대해 모든 뉴런 활성화 (고정 비용)
MoE 모델: 입력 타입에 맞춘 선택적 활성화 (동적 비용)
결과: 같은 크기의 모델이 2-3배 더 빠르고, 같은 속도로 더 큰 모델 수준의 품질 달성
기술 스펙과 경쟁력 상세 분석
Small 4의 강점
1. MoE 기술로 중형 모델 수준의 성능을 소형 리소스로 구현
- 매개변수: 1,600억 (이론) / 50억 (실제)
- 비교: GPT-3.5 (1,750억) 수준의 품질을 5배 더 적은 리소스로 달성
- MMLU 벤치마크: 85% (GPT-3.5: 70%, GPT-4: 86%)
2. 추론 속도 50% 개선
- 평균 생성 속도: 150 토큰/초 (기존 Small 3: 100 토큰/초)
- 응답 지연시간: 200ms 이하 (실시간 대화형 AI 가능)
- 배치 처리: 1000개 요청 동시 처리 (GPU 메모리 효율성)
3. 엣지/모바일 배포 최적화
- 모델 크기: 양자화 후 15GB (기존 Small 3: 35GB)
- 메모리 사용량: 8GB GPU에서 배포 가능 (NVIDIA L4)
- 배터리 소비: 기존 대비 40% 감소 (모바일 추론)
경쟁사 비교: Small 4 vs OpenAI vs Meta vs Google
| 기준 | Mistral Small 4 | OpenAI GPT-5.4 mini | Meta Llama 4 | Google Gemini 1.5 |
|---|---|---|---|---|
| 아키텍처 | MoE (128 Expert) | 밀집형 (Transformer) | MoE (?) – 미확정 | 멀티모달 |
| 매개변수 | 1,600억 (실제: 50억) | 140억 | 700억 (예상) | 1,700억 |
| MMLU 성능 | 85% | 88% | 84% | 92% |
| 추론 속도 | 150 T/s | 60 T/s | 80 T/s | 100 T/s |
| 컨텍스트 | 128K | 200K | 128K | 1,000K |
| 라이선스 | 오픈소스 | 독점 (API) | 오픈소스 | 독점 (API) |
| 가격 (1M 토큰) | 무료 (자체호스팅) | $0.15-$0.30 | 무료 (자체호스팅) | $0.075-$0.30 |
| 배포 옵션 | 온프레미스, 엣지 | 클라우드 API만 | 온프레미스, 엣지 | 클라우드 API + 일부 |
경쟁사별 전략 분석
OpenAI (폐쇄형 독점 모델)
- 강점: 최고 수준의 성능, API 안정성, Microsoft 생태계
- 약점: 비싼 가격, 온프레미스 배포 불가능, 데이터 프라이버시 우려
- 대응: GPT-5.4 nano/mini로 가격 경쟁력 강화 시도
Meta (오픈소스 공격)
- 강점: 무료 Llama 모델, 커뮤니티 확산, 온프레미스 배포 가능
- 약점: 성능 차이, 상용 지원 부족, 보안 이슈
- 전략: Llama 4 출시로 Small 4와 직접 경쟁
Google (멀티모달 우위)
- 강점: 최고 성능, 이미지/비디오 처리, 1000K 컨텍스트
- 약점: 가격대 높음, 규제 우려 (데이터 수집)
- 전략: 성능과 규제 준수의 균형
Mistral (오픈소스 + 엣지 중심)
- 강점: MoE 기술, 비용 효율성, 온프레미스 배포 완벽 지원
- 약점: 성능 격차, 기업 지원 제한적
- 전략: 엣지 AI와 엔터프라이즈 시장 수직 공략
산업 맥락 및 오픈소스 이점 강조
OpenAI/Google의 폐쇄형 API 정책에 대한 Mistral의 강공
폐쇄형 모델의 문제점
- 비용: 1000만 개 쿼리 처리 시 월 비용 $50,000 이상
- 종속성: OpenAI API 중단 시 서비스 마비
- 데이터 프라이버시: 쿼리 데이터가 OpenAI 서버 저장
- 커스터마이제이션: 자사 데이터로 미세 조정 불가능 또는 비용 극심
- 규제 리스크: EU AI Act, GDPR, 중국 AI 규제 등에서 API 의존 회피 필요
오픈소스 (Mistral Small 4)의 이점
- 비용 절감: 자체 호스팅으로 월 비용 $5,000 이하 (10배 저렴)
- 데이터 보안: 모든 쿼리가 사내 서버에서 처리 → 외부 데이터 유출 제로
- 규제 준수: GDPR, HIPAA 요구사항을 자체 제어로 충족
- 커스터마이제이션: 자사 데이터로 미세 조정 가능 (비용 1/100 이하)
- 독립성: 공급자 종속성 제거, 장기 전략 수립 용이
- 속도: 추론 지연시간 50% 단축 (온프레미스 배포)
온프레미스/엣지 배포를 원하는 기업들에게 새로운 선택지 제공
기업의 AI 배포 전략 변화
2026년 기업의 AI 도입 패턴 조사에 따르면:
- 클라우드 API 의존형: 20% (높은 비용, 데이터 보안 우려)
- 하이브리드 (클라우드 + 온프레미스): 60% (비용과 보안의 균형)
- 100% 온프레미스: 20% (완전 독립, 고비용)
Small 4는 60% 하이브리드 기업에게 이상적인 솔루션입니다.
개발자 커뮤니티 확보 → 기업 고객 유입 전략
Step 1: 개발자 채용 (2026년 상반기)
- GitHub에서 Small 4를 쉽게 배포 가능한 예제 코드 공개
- 스타트업 1000개에게 무료 호스팅 크레딧 제공
- 개발자 커뮤니티 슬랙, 포럼 활성화
- 결과: 개발자 커뮤니티 50만 명 이상 확보
Step 2: 기업으로의 확산 (2026년 하반기)
- 스타트업이 성공하면, 모회사 기업으로 확산
- “우리 팀이 Small 4로 만든 제품” → 기업용 라이선스 판매
- 기업 지원 (SLA, 보안 감시, 법적 책임) 서비스 출시
- 결과: 기업 고객 5,000개 이상 예상
Step 3: 생태계 확대 (2027년 이후)
- 클라우드 제공자 (AWS, Azure, GCP)의 Mistral 마켓플레이스 추가
- 산업별 SaaS 솔루션 (의료, 금융, 법률) 번들 제공
- AI 스타트업 가속기 프로그램 시작
비즈니스 기회 분석
클라우드 제공자의 수혜
AWS
- SageMaker에서 Small 4 마켓플레이스 판매
- 온프레미스 고객의 AWS 클라우드 이전 기회 (유연한 하이브리드 모델)
- 월 추가 수익: 약 $30M (Small 4 기반 서비스 호스팅)
Microsoft Azure
- 기존 GPT-4 고객을 Small 4로 비용 최적화
- Azure ML에 Small 4 런타임 추가
- 월 추가 수익: 약 $20M
Google Cloud
- 기존 고객 이탈 방지를 위해 Llama, Small 4 지원
- Vertex AI 플랫폼에 다중 모델 관리 기능 강화
엔터프라이즈 소프트웨어 기업
Salesforce, SAP, Oracle
- 기존 ERP/CRM에 Small 4 기반 AI 어시스턴트 내장
- 라이선스 비용 절감으로 고객 만족도 증가
- 각 사 연 $50M 이상의 신규 수익 창출
개발자 커뮤니티의 이득
- 오픈소스이므로 학습 자료 풍부
- 미세 조정, 양자화 등 커스터마이제이션 자유
- 상용화 시 로열티 없음
- LangChain, LlamaIndex 등 생태계와 통합 용이
엣지 디바이스 제조업체
- 스마트폰 제조사: 온디바이스 AI 기능 구현 (카메라, 음성)
- 로봇 제조사: 자율 이동, 물체 인식 기능
- IoT 기업: 스마트 센서, 스마트 홈 제어
시장 적용 사례
사례 1: 의료 기관 (Small 4 온프레미스 배포)
대학병원이 환자 기록, 의료 영상 분석에 Small 4 도입:
- 기존 비용: GPT-4 API로 월 $40,000
- Small 4 도입 후: 서버/운영 월 $8,000
- 절감액: 월 $32,000 (연 $384,000)
- 추가 효과: HIPAA 규정 자동 충족, 환자 데이터 보호
사례 2: 금융 회사 (멀티 모델 전략)
은행이 Small 4 (저비용) + GPT-5.4 base (고급 작업) 혼합 배포:
- 고객상담: Small 4 (비용 효율)
- 사기 탐지: GPT-5.4 base (성능 우선)
- 대출 심사: 소규모 미세 조정 모델 (Small 4 기반)
- 전체 월 비용: 기존 GPT-4 API 대비 60% 절감
사례 3: 제조사 (엣지 배포)
자동차 부품 제조사가 생산라인 품질 검사에 Small 4 배포:
- 불량품 탐지: Small 4 (실시간, 온프레미스)
- 네트워크 지연 제거 → 불량품 즉시 제거 가능
- 생산량 증가: 월 1% (즉시 조치로 인한 효율성)
- 회수 비용 감소: 월 $100,000 절감
위험 및 고려사항
1. 성능 격차 (소형 모델의 한계)
Small 4 (85% MMLU) vs GPT-5.4 base (92% MMLU)의 성능 차이는 특정 도메인에서 중요합니다:
- 의료 진단: 정확도 차이 5% = 환자 안전 문제
- 법률 분석: 정확도 차이 = 법적 리스크
- 금융 거래: 정확도 차이 = 손실
2. 커뮤니티 지원 부족
오픈소스이지만, 기업 지원이 제한적입니다:
- SLA (Service Level Agreement) 부족
- 버그 수정 시간이 OpenAI API (즉시 보상)보다 느림
- 보안 이슈 발생 시 패치 시간 불명확
3. 보안 및 라이선스 문제
- 오픈소스 모델의 데이터 출처 불명확
- 저작권 침해 가능성 (학습 데이터 포함)
- 기업 라이선스 명확성 부족
4. 기술 지원 및 유지보수
- 자체 호스팅 시 기술 팀 필요
- GPU 서버 관리, 모델 업데이트, 보안 패치 자체 담당
- 중소 기업에는 부담스러울 수 있음
향후 전망
단기 (2026년 상반기-말)
- Small 4 채택 기업 2,000개 이상
- GitHub 리포지토리 10만 개 이상 (Small 4 기반 프로젝트)
- 클라우드 제공자 (AWS, Azure, GCP) 모두 Small 4 마켓플레이스 출시
- Mistral 기업 수익 $5M 달성
중기 (2027년)
- Small 4 기반 SaaS 스타트업 500개 창립
- 포춘 500대 기업의 20% 이상이 Small 4 도입
- 오픈소스 AI 모델의 시장 점유율 25% 달성
- Mistral 시리즈 B+ 펀딩 $500M 이상 (유럽 AI 리더 위치 확립)
장기 (2028년 이후)
- 오픈소스 AI 모델의 폐쇄형 모델 성능 추격 완료
- 엔터프라이즈의 AI 지출 구조 변화: 독점 API 30% → 온프레미스 70%
- Mistral이 유럽의 OpenAI/Google 경쟁자로 자리잡음
- AI 시장의 “민주화” 완성 (모든 기업이 자체 AI 모델 운영 가능)
결론: 오픈소스 AI의 미래
Mistral Small 4의 출시는 AI 시장의 판을 바꾸는 신호탄입니다. OpenAI와 Google의 폐쇄형 독점 모델에 대한 강력한 도전입니다. 소형 모델 시장에서 오픈소스는 이제 “싼 대안”이 아니라 “기술적으로 우월한 선택지”가 되었습니다.
기업들은 더 이상 비용 대 성능의 양자택일이 아닌, 비용과 성능을 모두 확보할 수 있는 선택지를 갖게 되었습니다. 이는 AI 기술의 진정한 민주화이며, 향후 AI 산업의 구조를 근본적으로 재편할 것입니다.
향후 2-3년은 “오픈소스 vs 독점” 경쟁의 흥미로운 시기가 될 것입니다.
경쟁사 비교 및 기술적 차별화
OpenAI의 GPT-5.4 모델군은 높은 성능을 제공하지만 폐쇄형 모델이며 API 비용이 높다는 제약이 있습니다. Meta의 Llama 모델은 오픈소스이나 추론 효율이 떨어집니다. Mistral Small 4는 이 두 극단 사이의 균형점을 제시하며, 특히 128개 Expert Module의 MoE 구조를 통해 선택적 매개변수 활성화로 비용-성능 효율을 극대화합니다.
기술 심층 분석: MoE(혼합 전문가) 아키텍처
Mixture of Experts 기술은 거대 모델을 여러 개의 작은 전문가 네트워크로 분산시키고, 각 입력에 대해 가장 적합한 전문가만 활성화하는 방식입니다. Mistral Small 4의 128 expert 구성은 매우 세분화된 작업 분할을 가능하게 하여, 언어 이해, 수학, 코딩, 창의적 글쓰기 등 다양한 도메인에서 최적화된 성능을 발휘합니다.
산업 적용 시나리오
컨설팅 회사들은 Mistral Small 4를 고객사 온프레미스 환경에 배포하여 비즈니스 문서 분석, 계약서 검토, 시장 조사 리포트 자동화에 사용할 수 있습니다. 콘텐츠 제작 회사는 다국어 마케팅 카피 생성, 소셜 미디어 포스팅 자동화, SEO 최적화 콘텐츠 제작에 활용 가능합니다. 교육 기관은 학생별 맞춤형 학습 자료 생성, 학습 진도 평가, 개념 설명 최적화에 적용할 수 있습니다.
앞으로의 전망
오픈소스 LLM 생태계는 계속 진화할 것이며, Mistral의 지속적인 개선과 경쟁은 전체 AI 산업의 성숙도를 높일 것입니다. 기업들은 폐쇄형 고가 모델과 오픈소스 효율형 모델 사이에서 최적의 선택지를 가지게 됨으로써, AI 도입 진입장벽이 낮아질 것으로 예상됩니다. 특히 데이터 프라이버시가 중요한 산업(금융, 헬스케어, 정부)에서 Mistral과 같은 온프레미스 배포 가능 모델의 수요가 급증할 것으로 보입니다.